tl;dr WebAudio is a solid API with many features. It is easy to create complex effects (like pitching, panning and even dynamic music transitions). However, there are many small details to consider when dealing with browser variations. A battle proven wrapper like howler.js that takes care of the details is definitely a thing to consider. [DEMO is pending]
About
Working on my game Ghost Jump I came to the point where I needed to integrate sound and music. GhostJump is written in pure JavaScript and I think WebAudio is my best option. I have never used the API before but I do have some experience with audio programming. To get the full experience I decided to not start with a wrapper like howler.js or soundjs.
The WebAudio API is very powerful but also full of strange vendor specific behaviors. For example, it is not possible to create an AudioContext on iOS Safari or desktop Chrome if you are not in some kind of magic user input event context. This and other things I intend to explore and write about it here.
WebAudio at a glance
Without copying the entire API docs here let me try to summarize how I understand it. WebAudio is composed of a AudioContext that needs to be packed with Audio Nodes. When playing a sound effect or music one has to connect multiple audio nodes within the context. A node is an instance of a JavaScript object which’s parameter can be modified.
We have three types of audio nodes:
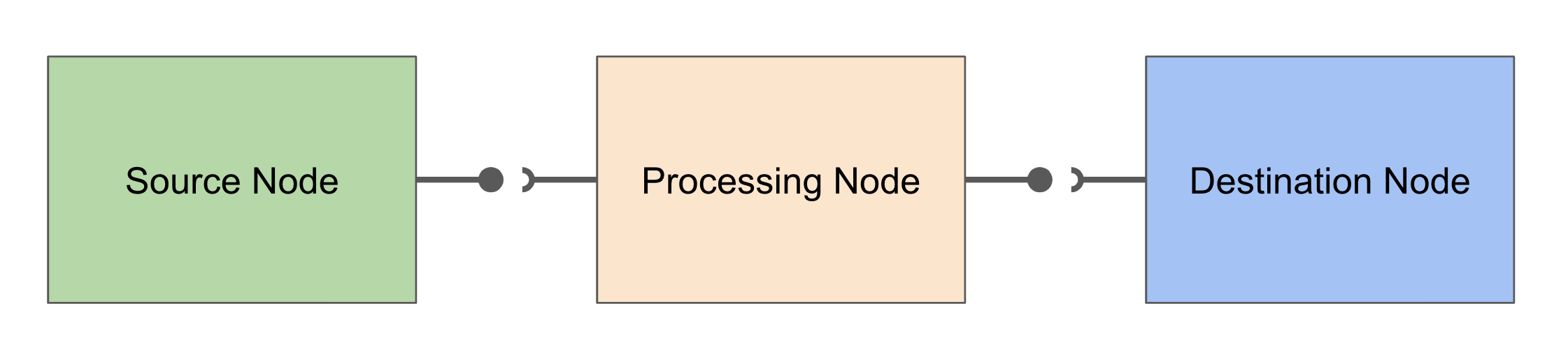
- Source Nodes input sound data from somewhere into the audio graph. For example
AudioBufferSourceNodetakes sound data from anAudioBufferand passes it on to the next node. As they all generate or read data from a foreign source they are always at the start. - Processing Nodes take data from other Processing or Source Nodes, modify the data somehow and pass it on.
- Destination Nodes read the final result and transform it to whatever. The most important candidate here is
myAudioContext::destinationwhich basically means play the music on the speakers.
Additionally to these types we have the classes AudioBuffer and AudioParam. An AudioBuffer can be created manually by filling data into the buffer. The more common approach is to load and decode an audio file (mp3, ogg, etc). AudioParams can be a simple number value. However, it is also possible set multiple changes over time. So they kind of a mixed bag: value and/or curve.
Playing a sound file, change the gain and also the panning would looks like this:
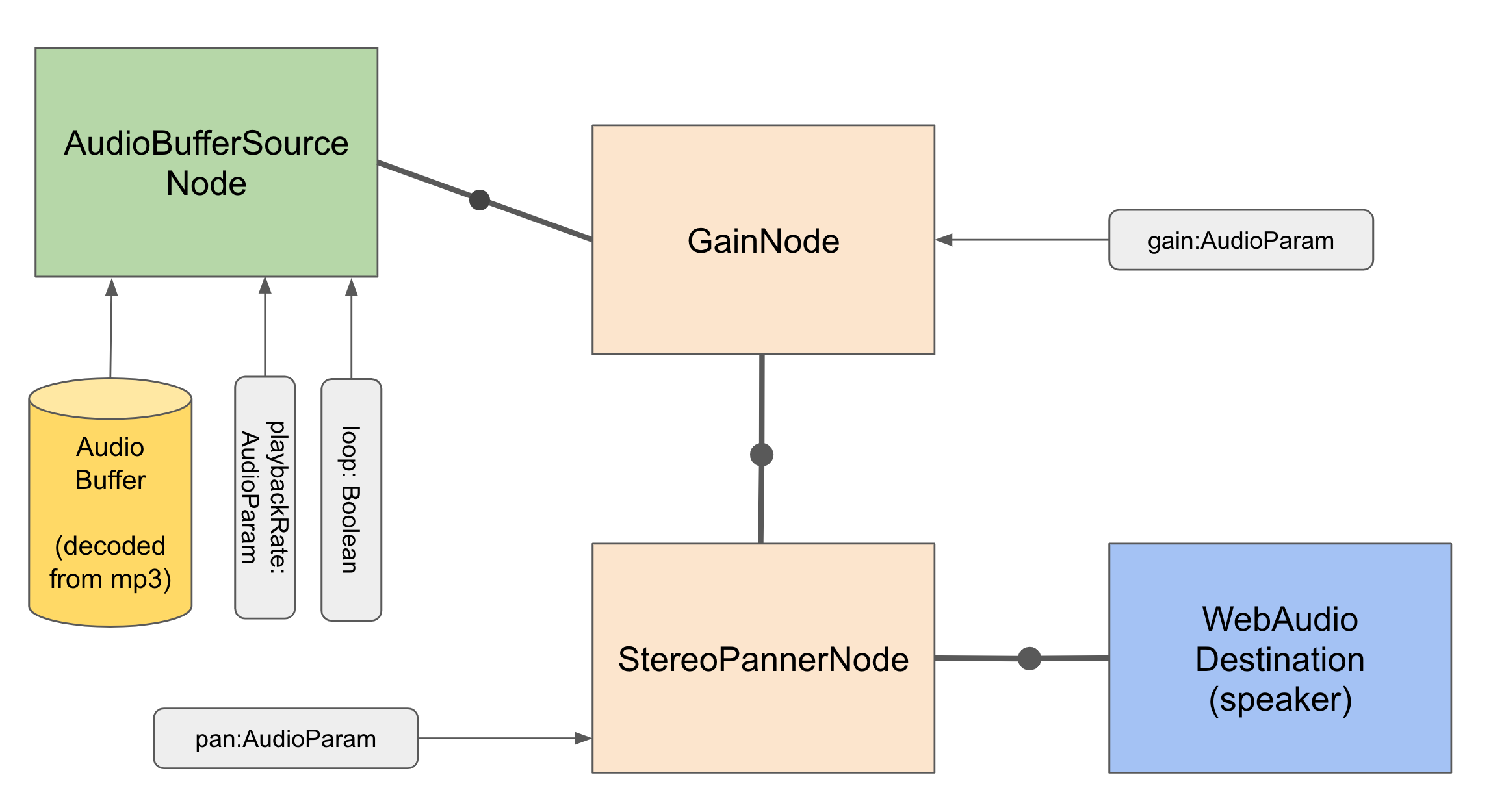
We need to decode an MP3 to an audio buffer and link it to an instance of AudioBufferSourceNode. Then we connect it with the two processing nodes GainNode and StereoPannerNode. Using the parameter loop, playbackRate, gain and pan on the nodes we can change the audio behavior. Lastly we connect it to the destination of the context so we can hear something.
I know already, that iOS Safari does not support the StereoPannerNode. So, if panning is required I hope to be able to use ChannelSplitterNode and ChannelMergerNode with two GainNode for each channel to support that.
What I like best about the concept is, that we use JavaScript only to setup the AudioGraph. The processing is all done in the native layer of the browser which should be fast.
Which features I need for gamedev
For Ghost Jump I just like to use the API and don’t want to build complex tools around it. From my experience with Unity and tools like wwise I know it can be a huge plus to be able to tweak nearly every aspect of the games’ sound effect while playing it. However, for this project it should be enough to just connect some Audio Nodes and have some parameters in the engine.
The following things I expect to work:
- Being able to make use of heavily compressed file formats such as
mp3oroggwith decoding support by the browser. - Sound effects should play low latency. If player mashes the jump button the sound just needs to be there without the tiniest pause.
- Sound effects should support panning, pitching and gaining
- At least one track background music should play with low load on the CPU
- All this without any memory leaks
- Also hope to have low impact on the garbage collector.
What I really want: Dynamic Music System
Looking at the gameplay this might be a big request, yes. Let me explain.
The main driving force of the game is the combo pressure. The game allows the player to play slow. Playing slow means that you take your time before you try to make a jump into the next room. If you play slow it’s easy to reach high floors and collect items that relate to the floor-level. However, if you manage to leave a room without changing the color more than once it means you increase your combobar. If you fill your combobar you increase your combolevel. The combolevel increases the score you get in each room. The way the rooms are built it means you have to be super quick and the stress level is very high.
I really think it would greatly increase the overall experience if I can modify the music based on that combolevel. It would just be awesome to have a cool catchy tune that is nearly silent or even muted but rises with the combolevel.
After studying the API and thinking about the problem I came up with three approaches that might work:
Simple Filter ApproachClever LoopingMultilayer Music
Simple Filter Approach
Using a BiquadFilterNode it is possible to apply a lowpass filter to the background music. If the music is produced correctly it should be possible to adjust the values with the combolevel as an input value. Additionally I can change the speed of the tune.
I call this approach simple, because it should more or less work with any tune and the WebAudio API offer the required effects.
Clever Looping
The AudioBufferSourceNode has native support for loopStart and loopEnd which can be modified while the music is playing (see here). If the precision of those two values are reliable we can modify them based on the current combolevels.
Start of the music file
| End of the music file
| |
v v
|----------||----------||----------|
(A) (B) (C)
The file is composed of 3 sections:
- (A) the low pressure loop, slow, comfy and nice
- (B) the mid pressure loop, more dynamic, faster
- (C) the high pressure loop, high power super active, catchy melody
When the level starts we set the loop values to (A.start) -> (A.end). As long as the player plays slow one will only hears the (A) part.
Once the combo level rises above a certain threshold the game changes the loop values to (A.start) -> (B.end). If the pressure stays and the music pointer reaches the (B) area the game changes the loop values to (B.start) -> (B.end).
If the combo level reaches the next threshold we do the same thing. We change the loop to (B.start) -> (C.end), wait for the music pointer to enter the (C) area and then change it to (C.start) -> (C.end). Now we loop (C) indefinitely.
When the player looses the combolevel and we are in the (B) or (C) area we simply change the loop values to (A.start) -> (B/C.end). Once we are back in (A) we set the loop values to (A.start) -> (A.end).
This idea is based on the expectation that we can rely on the loop-values of AudioBufferSourceNode as they fully controlled by the native part. The detection whether we reached a new area is not required to be super exact. I think using the progress value is good enough to figure out a proper time to modify the loop-values.
This approach has the advantage that we only need to play one file at a time. The downside is that the switches between the levels is not very direct. Depending on the play-cursor-position it may take some time to let the combolevel have an effect on the music. This could be mitigated by adding a filter or change the pitch.
Multilayer Music
This approach is based on the hope that WebAudio can handle at least two songs at the same time. It also requires the API to be able to perfectly sync those two tunes and switch them dynamically at runtime.
If that is the case we could try the following:
(A) |--------------------|
(B) |--------------------|
(C) |--------------------|
We need three (or more) music tracks:
- (A) the slow part
- (B) the faster part
- (C) the super active part
Each of them is an audio file. (A), (B) and (C) must have the same length and loop. At the start we play (A) in a loop. We also play (B) in a loop but with 0 gain. Now, when the combolevel starts to rise we start to increase the gain of (B) and decrease the gain of (A). We do that until we fully blended over to (B). If the compolevel rises even more we swop the AudioBuffer of (A) to ©. Then do the same as before and only with © and (B) this time.
So, basically we simply blend between the tracks from (A) to ©. Of course this only works when the compositions match. It is also super important that the swop of the AudioBuffer can be done without any glitches and in perfect sync.
Implementation in two parts
The implementation will have two parts. Part 1 is the implementation of the dynamic music effect. I hope that I can find some free composition so I can show the result here with a little demo on the page.
Part 2 will be the sound effects within the game. This code might be eventually part of my game engine TTjs but not right away. If you read this and you really want to see that part drop me an email.
Preparation: create an audio context
Before we start thinking about how to connect the nodes in a clever fashion to get the desired effects we have to setup a proper AudioContext.
Even though we are on a super high level: JavaScript there are still various things that can go wrong. We can learn about that by reading into the details of soundjs. I don’t intend to copy soundjs but its a good source to understand which quirks are required to get the AudioContext run properly on all devices.
Let me summarize the issues I can extract from there:
- iOS Safari (and since 2018 also desktop chrome), WebAudio only will play something when we played a sound at least once during a
mousedown,touchstartor antouchendevent - General, WebAudio only works when
XMLHttpRequestsare working. For example it won’t work when opened withfile://mygame.htmletc. However, this should work in a Cordova environment. - iOS Safari, on some iOS versions it is required to nudge the AudioContext a bit by playing a dummy buffer with the desired sample rate. Otherwise it can happen that it starts with a random sample rate which sounds ugly. They took it from ios-safe-audio-context.
When first read into this it sounded a bit complicated set of rules. However, I think all three issues can be handled in an easy fashion. Problem (1), the way I read it, only means the sound is muted. It is safe to use the AudioContext before you only won’t hear anything. Following the solution of soundjs is simply fixed with an empty buffer played on the given event. (3) requires us to do the same directly after creating the AudioContext.
Hm… I’m not 100% sure that the fix of (3) works without the events of (1). It really comes down to the question: is iOS just muting the output or does it actually prevent audio processing? Accordning to soundjs’ code iOS only mutes the sound. The example of ios-safe-audio-context says that (3) needs to be done during (1). I need to test that a bit.
As for (2) I really think thats an issue with Cordova wkwebview-engine. As WKWebView is required by Apple I need to investigate that. However, as this is a general issue and should be solved when dealing with iOS deployment on WKWebView in general.
So, for now we do the following:
- Experiment 1: Write a little test-app to see if iOS is preventing audio processing or just muting it.
- Experiment 2: Check if we can reproduce the issue of (1) one and see if the touch event fix works
Experiment 3: See if we can reproduce that the issue of (3) and see if the fix is working or not.This is already covered by (2). Read on.
Create Audio Context: Experiment 1
I start by simply create a context, play some music and do the touch event. If the music is already playing when the touch event occurs we can safely assume that iOS only mutes the output.
We begin by probing the format that we can load on the given browser. To do so we create an <audio> element and use its function canPlayType(). Like this:
<!DOCTYPE html>
<html>
<head></head>
<script>
// Determine the type
const testAudioElement = document.createElement("audio");
console.log(testAudioElement.canPlayType("audio/mp3"))
console.log(testAudioElement.canPlayType("audio/ogg"))
console.log(testAudioElement.canPlayType("audio/wav"))
</script>
</html>
I must admit I was totally astonished when I saw what this code printed to the console
maybe
probably
maybe
maybe and probably? What? Why? Ehm… okay, okay I get it. The browser cannot know because… no I actually don’t get it.
Reading into the specs it seems that probably > maybe and anything else means no. So, no promises here.
But back to the test.
Creating an AudioContext Chrome already informed me that there are states to consider.
REUSLT: No, the AudioContext is actually not really started. It is suspended and does not just mute the audio.
Create Audio Context: Experiment 2
Now let’s try to create the AudioContext in an input event context.
// global values (obviously I don't use it like this in the game ^^)
const globalAudioContext = null;
const inited = false;
const sampleRate = 44100;
const emptyBuffer = null;
// init the buffer
function init() {
if (inited)
return;
inited = true;
// create audio context
const AudioCtor = (window.AudioContext || window.webkitAudioContext);
globalAudioContext = AudioCtor ? new AudioCtor() : null;
// create empty fake buffer in the right sample rate
emptyBuffer = globalAudioContext.createBuffer(1, 1, sampleRate);
// play it once to make sure sample rate is set
// AND the sound is unmuted.
const source = globalAudioContext.createBufferSource();
source.buffer = emptyBuffer;
source.connect(globalAudioContext.destination);
source.start(0, 0, 0);
// enjoy usign the API
}
// register events to actually enable sound playing
document.addEventListener("mousedown", init, true);
document.addEventListener("touchstart", init, true);
window.addEventListener("touchend", init, true);
REUSLT: Yes, this actually works on Chrome, my iOS device, Desktop Safari and Desktop Firefox.
Discussion
Creating an AudioContext object can only really work if we are in the context of a user input event. We can create it beforehand but it is kind of useless in suspended mode.
It might still be of value to create the AudioContext early so we are able to load the sound effects even though we can’t play them. However, try to play something before that will not work at all.
For me this leads to the conclusion that I really want to force the user to touch something early on in the game. That way we have a valid and reliable AudioContext object even if the user decides to play without sound.
Also watching James Simpson’s howlerjs video and reading into the howler source code. It seems WebAudio has a wide range of issues depending on the platform and operating system version.
Dynamic Music: Preparation
With the AudioContext working we can go on and start to work on the dynamic music approach. Before I actually try one of the given attempts we need to prepare the music assets for that.
To start with I picked some free music tunes from opengameart.org. I converted each file from wav to mp3 and to ogg. Using the incredible tool sound eXchange (installed via homebrew on macos).
# navigate into the directory and write:
sox fancy_cake.wav fancy_cake.ogg
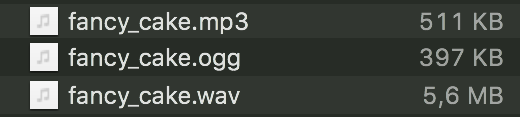
An mp3 or ogg file is about 10 times smaller than the raw wav file. It really is important to me that I can distribute the files in compressed form. The wav file I use for debugging. It also gives as a very good estimation how much memory it’ll cost when loading them into the RAM as a raw AudioBuffer.
Dynamic Music Attempt 1: Use WebAudio Filter
This is based on the idea that we can simply apply a filter. We then connect the stress level with the filter configuration.
From playing around with the examples I found on the web (like this) I found that BiquadFilter is a good candidate. IIRFilterNode is not available on iOS.
To create such a filter we can create it and connect it like this:
// create source
var source = globalAudioContext.createBufferSource();
var buffer = loadedAudioBufferFromSomewhere;
source.buffer = buffer;
// create filter and set it to lowpass
var filter1 = globalAudioContext.createBiquadFilter();
filter1.type = "lowpass";
// connect source + filter to the context (speaker)
source.connect(filter1);
filter1.connect(globalAudioContext.destination);
The next step is to transfer the combolevel (or stress level) to the filter properties.
// need to be called once-per-frameish (depends on engine, game etc.)
// val << 0-1 normalized stress level
var freqRange = 22050;
var freqVal = Math.min(100 + ((val * val)*freqRange), 22050);
filter1.frequency.value = freqVal;
This worked pretty straight forward. I tried different filter types and also changed the playbackRate of the source but eventually I found only lowpass filter and frequency changes useful.
Technically this is useable.
Dynamic Music Attempt 2: Clever Looping
The first part of the loop implementation was pretty simple. Again I loaded the music as an AudioBuffer.
For better debugging i created a sound file using Audacity that provides my (A), (B) and (C) part. As placeholder for the loops.
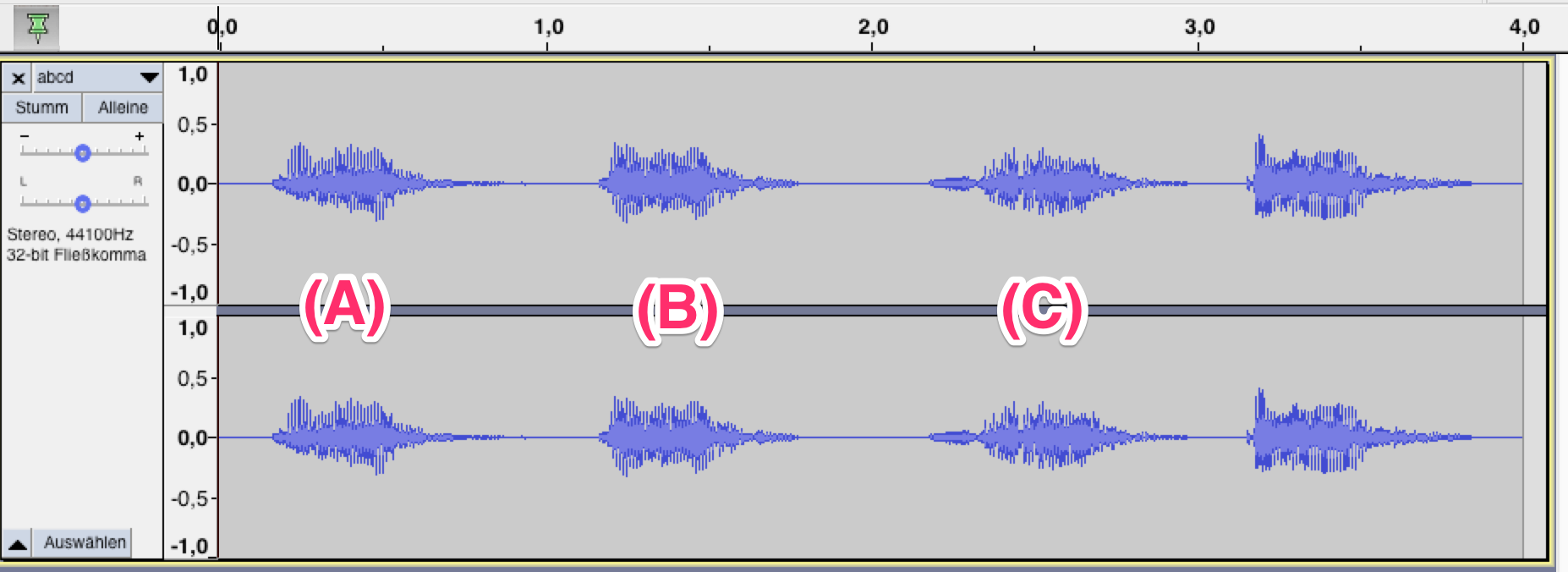
Further, I created an AudioBufferSourceNode and start by setting the loopStart and loopEnd values.
// create source
var source = globalAudioContext.createBufferSource();
var buffer = loadedAudioBufferFromSomewhere;
source.buffer = buffer;
source.connect(globalAudioContext.destination);
source.start(0);
// store the ranges
var MIN = 0;
var MAX = 0;
var ranges = [
[0, 1], // (A)
[1, 2], // (B)
[2, 3], // (C)
]
// setting the loop to the (A) part
source.loopStart = ranges[0][MIN];
source.loopEnd = ranges[0][MAX];
This works like it should. The next part is to dynamically update the loopStart and loopEnd values according to the combolevel.
This was an unexpected challenge. There is no playbackPosition or something in an AudioBufferSourceNode. That means you cannot simply ask the AudioBufferSourceNode what second you are currently playing. We need to take care of that on our own by using AudioContext.currentTime.
If you wonder why the playbackPosition is missing you can find the details in this discussion which can be found on the official (?) W3C github repo:
Exposing a playbackPosition property on AudioBufferSourceNode. It seems exposing a playbackPosition in a general W3C-spec compatible way is not an easy task. They have good arguments why the value isn’t just there.
The good news is that by using AudioContext.currentTime you can track the cursor play position. I was able to setup some test code to make it work and found no glitches.
Dynamic Music Attempt 3: Multilayer Music
Before I even start to implement this I must point to the WebAudio github repo again. Specifically this entry by cwilso is of importance:
Quote: The solution is that you shouldn’t hardly ever call start(0) for anything you want to synchronize. (cwilso)
But let’s start with the tracks.
To be meaningful the multi layer approach requires three or more music lines that can be played in parallel. Let’s imagine we have 3 music tracks. We could simply create an AudioBufferSourceNode for each of them and mute 2 (by setting gain to 0). We then change the gain of the nodes according to the combolevel. However, doing so could be very CPU intense because they still all have to be processed. Think older Android CPUs that already have to do all the game JavaScript as the same time.
A more CPU friendly approach is to only have two music layers active. The main layer and the blend layer. We always play the main layer and depending on the blend value we play the blend layer both with different gain values. When ever we want to switch to a different AudioBuffer we need to start a new AudioBufferSourceNode and sync it perfectly the main layer. The main challenge I see here is to keep track of the play cursor using AudioContext.currentTime.
It turned out that the approach suggested by cwilso actually works pretty well. This is the main thing we need to do:
var batchTime = context.baseLatency || (128 / context.sampleRate);
var startTime = 0; // global
if (firstRunTime) {
// Start the first buffer
var now = context.currentTime;
startTime = now;
source.start(now + batchTime); // (1)
}
else {
// later
var now = context.currentTime;
var offset = (now + batchTime - startTime) % mainBufferDuration;
source.start(now + batchTime, offset); // (2)
}
The key part here is (1). When we play the first loop, we do not use start(0) but instead we schedule the music a tiny bit in the future. now is the current time of the AudioContext and batchTime is the base latency. This mitigates small differences of currentTime that can occur due to different threads (JavaScript-thread vs. WebAudio-thread). The user won’t hear this. If we then, later, at any time add a second buffer (for our blend layer) we use the passed time now + batchTime - startTime and mod it by the buffer duration to calculate the offset position for the track (see (2)). Again, we set a very small schedule time to make sure it all get’s synced on the native layer.
This actually works pretty well.
Conclusion + Demo
The WebAudio API turned out to be very stable. It is powerful, fast and at least on my test devices pretty compatible.
However, before I even start with the implementation of the second part (the single sound effects) I stop here. Learning the API and the many details that need to be consider on the devices and browser versions I decided to make use of howlerjs. It takes care of all the little details and is reasonable fast. Their fallback method to HTML5 is a nice feature which helps to make it extra compatible (e.g. you cannot use WebAudio on iOS8 devices - as it might crash the WebView, etc.).
My approaches to dynamic music can still be used as Howler.js offers direct access to the WebAudio context.
As for the demo code I’ll put that online as soon as I figured out if I’m allowed to upload the music tracks I used :-)