About
I always had that idea of writing my own Quick Basic interpreter. A few weeks ago I did exactly that and like to share a bit of my experience. The Quick Basic (or QB) I used to know is Microsoft’s Quick Basic 4.5. If I write about QB I mean that particular version running on MS-DOS PCs.
Keep in mind that I’m no interpreter expert. If you search for a complete explanation how to do this right read this: Crafting Interpreters. It’s gold.
Goal: Make my game Marlor deployable
In an age and times of great pressure and distress I channeled my energy into a game project called MARLOR - The Master of Evil. Without internet and no Indiegamedev scene I started to built this gigantic love letter to Zelda and mixed it with elements from Secret of Mana and even Panzer Dragoon Saga (yep, I still have a copy ;-).
Years later, today, the game cannot be played anymore for various reasons. Not having a QB interpreter is one of them. My idea was to write an interpreter that is good enough to run my Marlor source code.
Required QB features
QB was meant for MS-DOS and therefore is heavily designed around Microsoft’s well known operating system. Luckily Marlor ignores most of those features and I only needed a subset of QB’s features.
Here is a list:
| QB Feature | Description |
|---|---|
| Variables | Basic variable types: SHORT (16 bit signed integer), LONG (32 bit signed integer), SINGLE (32 bit float), DOUBLE (64 bit double) and String (8 bit DOS encoded characters) |
| Typing notation | In QB a variable is introduced by a% = 10. % means that a is of type SHORT. Each variable type has it’s own character:
|
| Implicit type | QB also allows to just write: a = 10. In this case a is of type SINGLE which is the implicit default type. |
| Change implicit type | Using DEFINT A-Z one can change the default type to INTEGER. |
SUB |
Is like a function in other programing language but it cannot return a value. A sub can only be used as a statement and not be part of an expression. |
FUNCTION |
Is like a SUB but it needs to have a return value. It cannot be used as a statement and only be part of an expression. |
DIM |
The ability to create arrays. QB allowed not just simple stream of numbers but also crazy stunts like multi dimensional arrays with negative indices. |
DIM SHARED |
The SHARED keyword makes variable from the main-scope available to functions and subs. |
| File access | To load game files and write save games we need file operations. OPEN FOR INPUT, PRINT #1, INPUT #1 and CLOSE #1 are needed other IO features are not. |
| Built-in functions | QB implement it’s standard library into the language itself. To avoid implementing the full instruction set an API is needed that allows quick addition of those instructions the game actually requires. |
| ANIMATION QB+ 2.0 | Instead of using the standard QB graphic features I bought a graphic extension for QB. It was built by Christof Hinterseer from Germany and it supported advance graphic features like: 128 Sprites, display PCX images, custom fonts, Palette effects and more. All in MCGA (320x200 pixel @ 256 colors). Marlor makes heavy use of them. |
READ and DATA |
A way to put application data into the source code |
The feature rich part of QB’s standard graphics API can be left out. The sprite extension is simple to imitate with modern hardware.
What about existing solutions?
There are other solid QB re-implementations out there.
QB64
QB64 does an incredible job. It compiles BAS files into CPP code and allows GCC to create machine code. It is super compatible with QB and allows access to hardware accelerated graphics.
I gave it a shot but decided against. The idea of rewriting the Animation QB+ part in a C++ environment for different platforms wasn’t very tempting. Digging into the graphic details of operating systems and again think about things like OpenGL deprecation on macOS and having no support for iOS or Android was the main blocker for me. Also, Marlor is based on a certain trick to work around 64KB limit of BAS files which would be especially complicated to redo in the compile approach QB64 follows.
WWWBasic
WWWBasic makes BASIC available in the browser. It already can handle complexe BAS files and supports many graphic details.
I started to run some of Marlor’s code inside WWWBasic and made awesome progress. However, language features were missing or buggy (e.g. no EXIT FOR, DEFINT A-Z had a bug and more). I tried to fix those issues and ended up preprocessing my QB code to something that WWWBasic can handle without modifications (e.g. replaced EXIT FOR with GOTO instructions). But it all felt like hacks. Additionally I really feel that JavaScript isn’t a good platform to deploy games. It could be, but as time of writing this, it isn’t.
Research
I’m not used to write interpreters. All I wrote so far was simple things like SchnackScript. The first thing I read about interpreters was the article: How compilers and interpreters work & what’s the difference? written by Rexcellent Games. It re-ignited the idea of writing a new backend for my game.
Getting deeper into the topic I found Computer Science’s Youtube videos about compilers very helpful:
- Part 1: Overview of the Stages of Compilation
- Part 2: Lexical Analysis
- Part 3: Syntax Analysis
- Part 4: Intermediate Code
Implementation
I selected C# as implementation platform because I like the idea of using Unity for deploying the game to the target devices. I started the project in Rider using .NET Core on macos. This allowed me to quickly debug and setup some test environment without having to deal with Unity specifics.
I basically followed the steps laid out in Computer Science’s Youtube videos.
Lexer
This is the first element that receives the source code. It takes the given characters of the *.BAS files and performs a very first categorization of each of them.
It eliminates all none relevant information like white space characters and comments. It makes it simpler for the next step (the parser) to do it’s job. We cannot ommit end of line EOL because QB needs it to detect inline-if-conditions.
To test my interpreter I created a syntax highlighter based on my tokens which is exported to HTML.
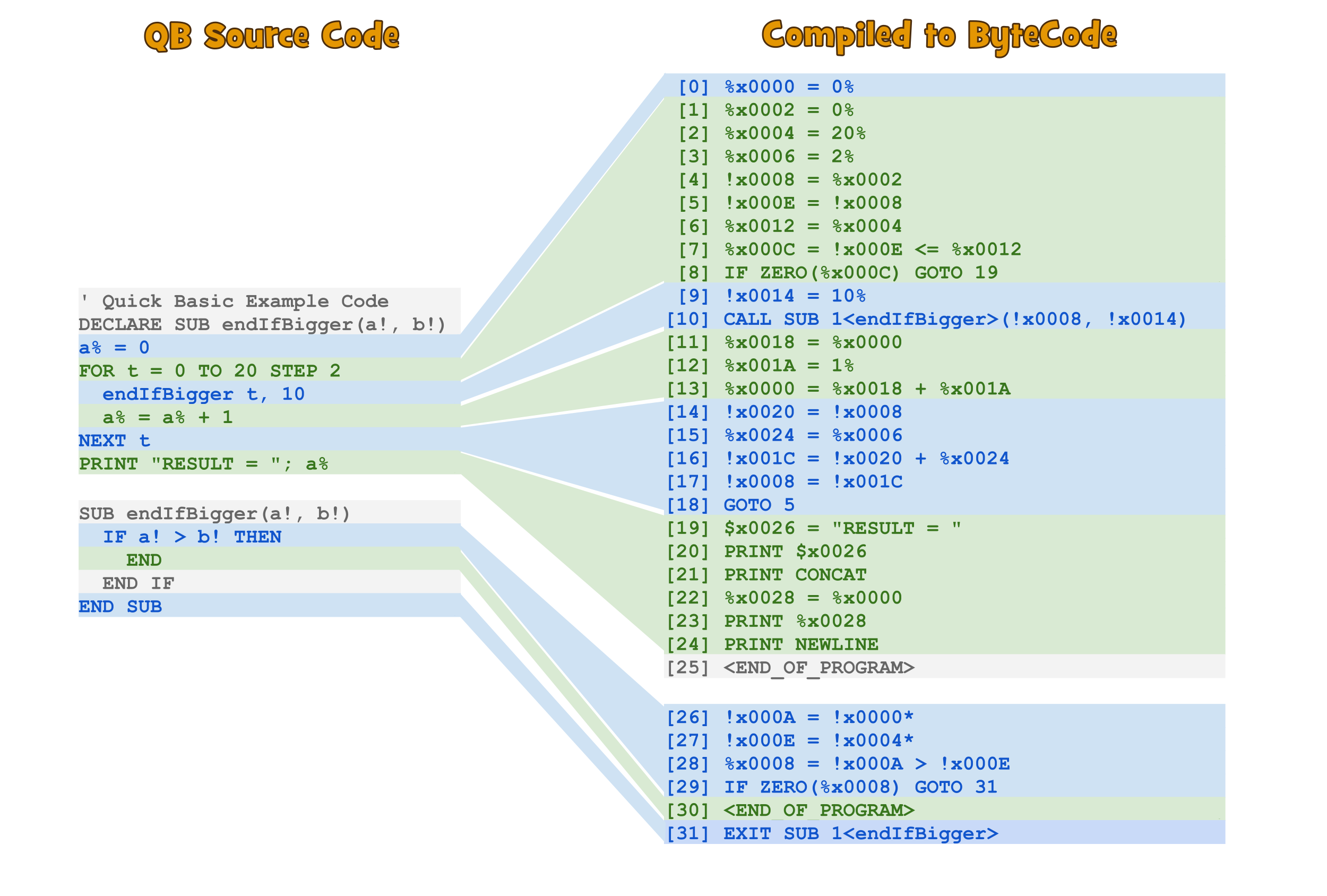
QB example source code
REM Quick Basic Example Code
DECLARE SUB endIfBigger(a!, b!)
a% = 0
FOR t = 0 TO 20 STEP 2
endIfBigger t, 10
a% = a% + 1
NEXT t
PRINT "RESULT = "; a%
SUB endIfBigger(a!, b!)
IF a! > b! THEN
END
END IF
END SUB
Lexer output

Parser (Abstract Syntax Tree)
The parser is implemented to take over the stream of tokens generated by the lexer. It then transforms it into an abstract syntax tree (or AST for short). The AST I implemented as a tree of c#-objects similar to what the DOM is for HTML. It represents the hierarchical structure of the source code. It also retains some meta data from the lexer so we can use that later for debugging and better error output.
A very tricky and challenging part (at least for me) was the evaluation of expressions. Luckily I found help. Bob Nystrom wrote this amazing article about parsing expressions which helped me to implement all those crazy details when it comes to expression parsing.
Abstract Syntax Tree output
To have a visual representation here I wrote an XML exporter of my abstract syntax tree objects. Here is the same code example from before:
<MAIN>
<ASSIGN_VAR name = "a%">
<VALUE>
<NUMBER val="0" />
</VALUE>
</ASSIGN_VAR>
<FOR var = "t!">
<START>
<NUMBER val="0" />
</START>
<END>
<NUMBER val="20" />
</END>
<STEP>
<NUMBER val="2" />
</STEP>
<BLOCK>
<CALL_SUB funcName="endIfBigger">
<PARAM index="0">
<READ_VAR name = "t!"/>
</PARAM>
<PARAM index="0">
<NUMBER val="10" />
</PARAM>
</CALL_SUB>
<ASSIGN_VAR name = "a%">
<VALUE>
<BINARY op="PLUS">
<READ_VAR name = "a%"/>
<NUMBER val="1" />
</BINARY>
</VALUE>
</ASSIGN_VAR>
</BLOCK>
</FOR>
<PRINT>
<STRING val="RESULT = " />
<SEMICOLON />
<READ_VAR name = "a%"/>
<EOL />
</PRINT>
</MAIN>
<endIfBigger>
<IF>
<CONDITION>
<BINARY op="BIGGER">
<READ_VAR name = "a!"/>
<READ_VAR name = "b!"/>
</BINARY>
</CONDITION>
<BLOCK>
<CALL_SUB funcName="END">
</CALL_SUB>
</BLOCK>
</IF>
</endIfBigger>
ByteCode Compiler
Theoretically it would be possible to execute the given code directly on the abstract syntax tree. However, while developing this I decided to go a further step and generate byte code (or classes that are effectively byte code).
This is done by traversing the AST and generate for each step a very simple instruction representation. It is basically the three address code approach but I sometimes I took a short cut to simplify my code. The memory management is done by a single stack object. Every variable is mapped to an address of the stack. That way all operations can be done by simply modify a value at a specific address. To read or write a variable no hashmap lookup is required. Structures like FOR-NEXT and DO-LOOP were mapped to JUMP-NOT-ZERO and GOTO instructions. That way the required byte code instruction set becomes very small.
This might sound very complicated and… well it actually was. It’s out of the scope to explain all the details here but I hope the following screenshot makes clear what happens:
Interpreter
The interpreter only has to execute the given byte code instructions. The byte code instructions are designed with the visitor pattern and the interpreter is implemented as a consumer for that.
Here is the list of byte code instructions I ended up with:
public interface IQBByteCodeVisitor
{
void Visit(QBCAssignConstShort visitor);
void Visit(QBCAssignConstLong visitor);
void Visit(QBCAssignConstSingle visitor);
void Visit(QBCAssignConstDouble visitor);
void Visit(QBCAssignConstString visitor);
void Visit(QBCAssignFromVariable visitor);
void Visit(QBCOperation visitor);
void Visit(QBCConcatStrings visitor);
void Visit(QBCNegation visitor);
void Visit(QBCBooleanNot visitor);
void Visit(QBCGoto visitor);
void Visit(QBCGosub visitor);
void Visit(QBCReturn visitor);
void Visit(QBCEndOfProgram visitor);
void Visit(QBCConditionalJump visitor);
void Visit(QBCDetermineIndexForDim visitor);
void Visit(QBCAllocateArray visitor);
void Visit(QBCCallSub visitor);
void Visit(QBCExitSub visitor);
void Visit(QBCStoreReference visitor);
void Visit(QBCCallFunc visitor);
void Visit(QBCExitFunc visitor);
void Visit(QBCFileOperation visitor);
void Visit(QBCFileWrite visitor);
void Visit(QBCFileRead visitor);
void Visit(QBCPrinter visitor);
}
Functions like LTRIM$, PRINT or SPRITEON need to be handled by the application and need to be injected into the interpreter. That way they I can implement them in Unity in a way that works best for the game.
State and Performance
In its current state the interpreter can run my game code. I have implemented all aspects except for the visual part. The next step is to integrate all that code into Unity and make the actual game.
As for performance, I haven’t done any measurement yet but running my game code it seems to be extremely fast. I’m convinced it’ll run my game without any further optimizations.
There is room for optimizations though:
- Byte code creates many unneeded tmp vars
- Visitor pattern might be slower than a gigantic switch
- Implement missing QB features (QB classes, implicit pass-by-reference of array elements, POKE, etc.)
That’s BASICally it for now. I’v got a working environment for my purpose and now I need to take care of other things. I really loved every second of this project and hopefully can get back to it soon. If so, I write about it.
Drop me a line via cschnack@gmx.de or @xtoffsgamestuff to share your thoughts.